Autonomous JSON Database(이하 AJD)
AJD는 ATP(OLTP), ADW(DW)와 동일하게 OCI의 Autonomous Database Platform 기반으로 제공되는 클라우드 데이터베이스 서비스이며, JSON 위주의 어플리케이션 개발/운영에 사용됩니다. ADB Platform의 장점인 고성능과 빠른 무중단 스케일업을 동일하게 제공하며, JSON 위주의 개발을 지원하기 위해 Document API를 제공하면서 추가로 트랜잭션 ACID나 SQL의 활용을 지원합니다.
AJD는 JSON 데이터 위주의 데이터베이스이기 때문에 ATP보다 휠씬 저렴한 비용으로 사용할 수 있으나, 관계형 데이터인 경우 20GB로 사용이 제한됩니다. 더 많은 관계형 데이터와 JSON 데이터를 혼용하여 데이터베이스를 운영하고 싶다면, AJD를 ATP로 전환하여 사용을 할 수 있으며 이 때 기존 AJD의 모든 기능을 그대로 유지됩니다.
앞서 설명한대로, AJD에서 JSON Docuement를 사용하기 위해서 아래 2가지 API를 제공하고 있으며, ADB에서 제공되는 RESTful Services를 이용하여 개발을 할수도 있습니다.
1. Simple Oracle Document Access (SODA)
2. Oracle Database API for MongoDB (also called the MongoDB API)
제공되는 API와 RESTful Services에 대한 상세한 내용은 다음 글에서 자세히 알아보고, 이 글에서는 AJD를 생성하고 SODA API를 이용해서 간단한 데이터조작을 해보도록 하겠습니다.
AJD 생성을 위해서는 아래 정보가 필요합니다. ADB와 동일하며, Workload Type을 JSON으로 선택하는 부분이 다릅니다.
- Compartment
- Name of Service
- Workload Type
- Deployment Type
- Database Version
- CPU Count, Storage Size
- ADMIN Password
- Backup, Network, DB License Configuration
로그인한 OCI 콘솔에서 좌측 햄버거 메뉴를 이용해서 "Oracle Database" -> "Autonomous Database" 메뉴로 이동합니다.

영문이 불편할 경우 우측상단 지구본 아이콘을 통해 한글로 언어를 변경합니다.
자율주행 JSON 데이터베이스로 이동해서 생성버튼을 클릭합니다.
다른 ADB와 생성화면은 동일하며, 컴파트먼트/데이터베이스 이름 등을 입력하고 워크로드 타입을 JSON으로 선택합니다.
데이터베이스 구성과 관련해서 버전 / CPU Count / Storage Size / Auto-Scaling 설정 / 백업 보관 기간 등을 선택합니다.
관리자 암호, 데이터베이스의 네트워크 환경도 추가로 선택합니다.
테스트 환경이므로 외부 공인망 접속을 허용하는 형태로 선택하여 진행합니다. 공인망 접속을 허용할 경우 데이터베이스 접속을 위해서 mTLS 인증이 필수 입니다.
오라클 데이터베이스 라이센스 설정, 관리자 연락처 등을 추가로 입력합니다.
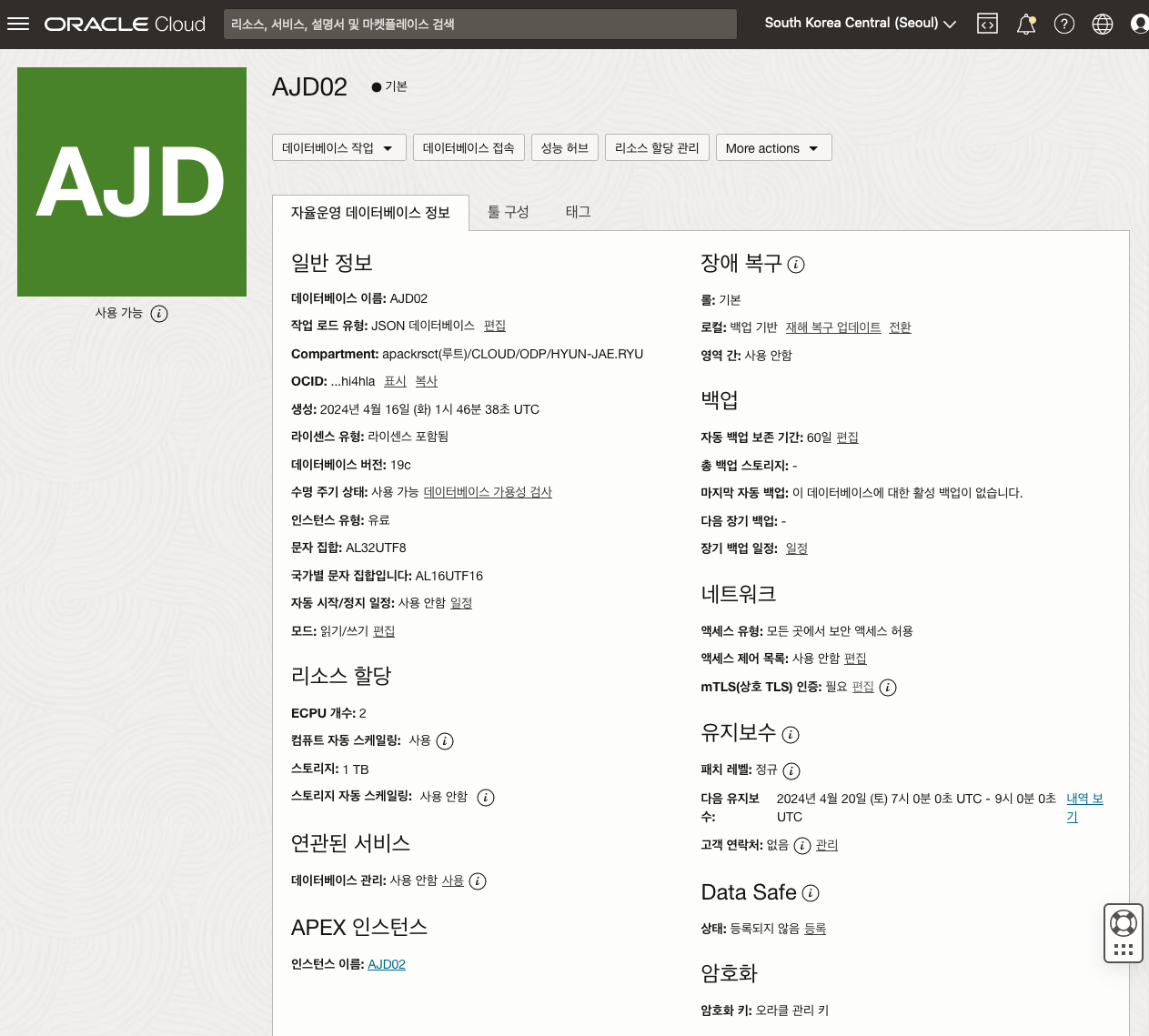
생성 버턴을 누르면, 잠시 후 데이터베이스가 바로 생성되고 메인 페이지에서 관련 구성 정보를 확인할 수 있습니다.
저는 데이터베이스 생성에 2분정도 소요되었습니다.
AJD에 생성이 된 후 함께 제공되는 Database Toolkit인 "Database Action"에서 제공되는 SQL Developer Web에는 SODA API가 내장되어 있어 바로 사용이 가능합니다. 해당 툴을 이용해서 간단하게 JSON 데이터 입력하고 조회해보겠습니다.
데이터베이스 작업에서 SQL로 이동합니다. 초기에 별도로 생성한 데이터베이스 유저가 없다면 생성 시 입력한 패스워드를 이용해서 관리자로 접속합니다.
웹 기반의 SQL Developer 를 사용하실 수 있습니다.
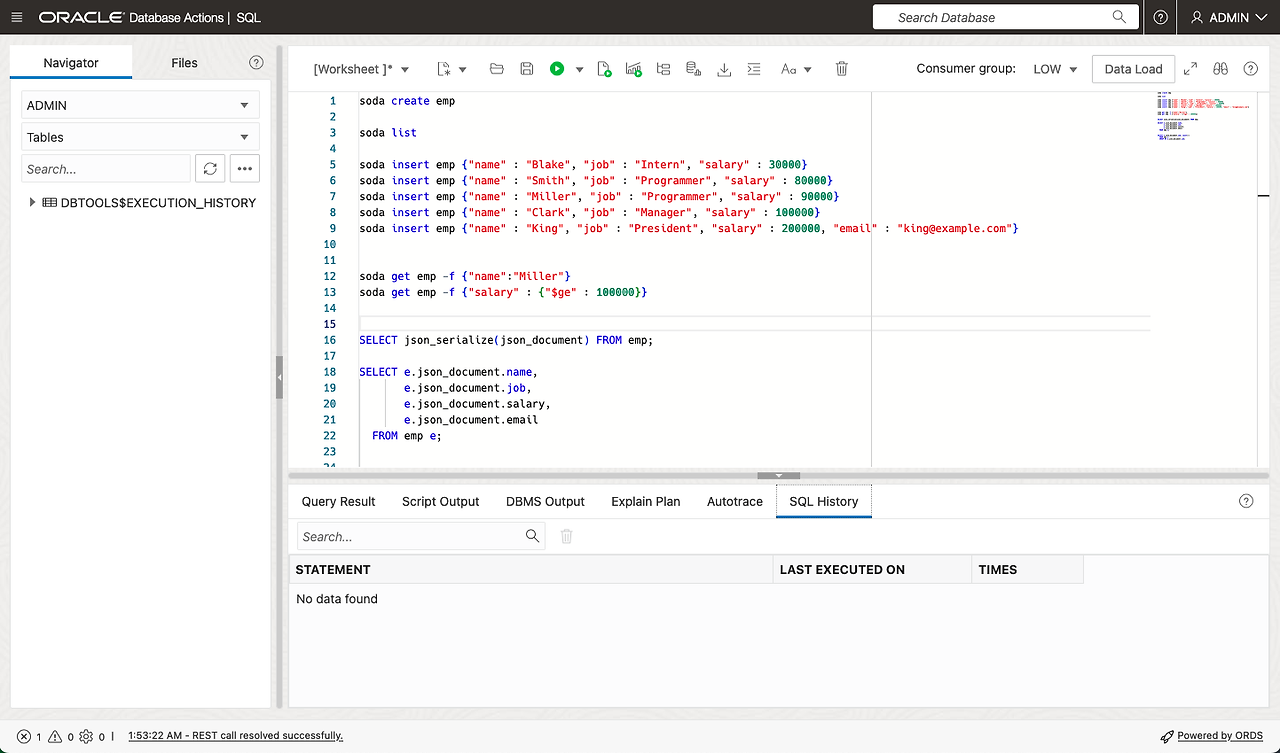
테스트 코드입니다.
SODA API를 이용해서 EMP라는 collection을 생성하고 JSON document를 Insert 한 후에 조회해보았고, SQL을 활용해서조 조회해보았습니다.
-- 테스트 코드
soda create emp
soda list
----
soda insert emp {"name" : "Blake", "job" : "Intern", "salary" : 30000}
soda insert emp {"name" : "Smith", "job" : "Programmer", "salary" : 80000}
soda insert emp {"name" : "Miller", "job" : "Programmer", "salary" : 90000}
soda insert emp {"name" : "Clark", "job" : "Manager", "salary" : 100000}
soda insert emp {"name" : "King", "job" : "President", "salary" : 200000, "email" : "king@example.com"}
----
soda get emp -f {"name":"Miller"}
Key: 0ACE52B438624C4185CE05B9E6515D51
Content: {"name":"Miller","job":"Programmer","salary":90000}
-----------------------------------------
1 row selected.
Elapsed: 00:00:00.054
----
soda get emp -f {"salary" : {"$ge" : 100000}}
Key: CABE85CB71AA496B9788F0EA64D88DC5
Content: {"name":"Clark","job":"Manager","salary":100000}
-----------------------------------------
Key: B7BB9A00BFBE421BB4CD29EA03365C3C
Content: {"name":"King","job":"President","salary":200000,"email":"king@example.com"}
-----------------------------------------
2 rows selected.
Elapsed: 00:00:00.052
----
SELECT json_serialize(json_document) FROM emp;
JSON_SERIALIZE(JSON_DOCUMENT)
----------------------------------------------------------------------------
{"name":"Blake","job":"Intern","salary":30000}
{"name":"Smith","job":"Programmer","salary":80000}
{"name":"Miller","job":"Programmer","salary":90000}
{"name":"Clark","job":"Manager","salary":100000}
{"name":"King","job":"President","salary":200000,"email":"king@example.com"}
Elapsed: 00:00:00.009
5 rows selected.
----
SELECT e.json_document.name,
e.json_document.job,
e.json_document.salary,
e.json_document.email
FROM emp e;
NAME JOB SALARY EMAIL
------ ---------- ------ ----------------
Blake Intern 30000 null
Smith Programmer 80000 null
Miller Programmer 90000 null
Clark Manager 100000 null
King President 200000 king@example.com
Elapsed: 00:00:00.007
5 rows selected.
----
SELECT e.json_document.job, count(*)
FROM emp e
GROUP BY e.json_document.job;
JOB COUNT(*)
---------- --------
Intern 1
President 1
Programmer 2
Manager 1
Elapsed: 00:00:00.006
4 rows selected.
개인 시간을 투자하여 작성된 글로서, 글의 내용에 오류가 있을 수 있으며, 글 속의 의견은 개인적인 의견입니다.
'3. 데이터관리' 카테고리의 다른 글
| Oracle Database API for Mongo DB 살펴보기 (0) | 2024.05.07 |
|---|---|
| OCI Data Integration 활용 - Data Integration Task 생성 (0) | 2024.04.29 |
| OCI Database with PostgreSQL Overview (0) | 2024.04.02 |
| OCI Data Integration 활용 - Data Loader Task (0) | 2024.04.01 |
| Oracle 데이터베이스 보안 솔루션 #2 - Data Safe (1) (0) | 2024.04.01 |




댓글